
Service Health Monitoring Improves Infrastructure Predictability
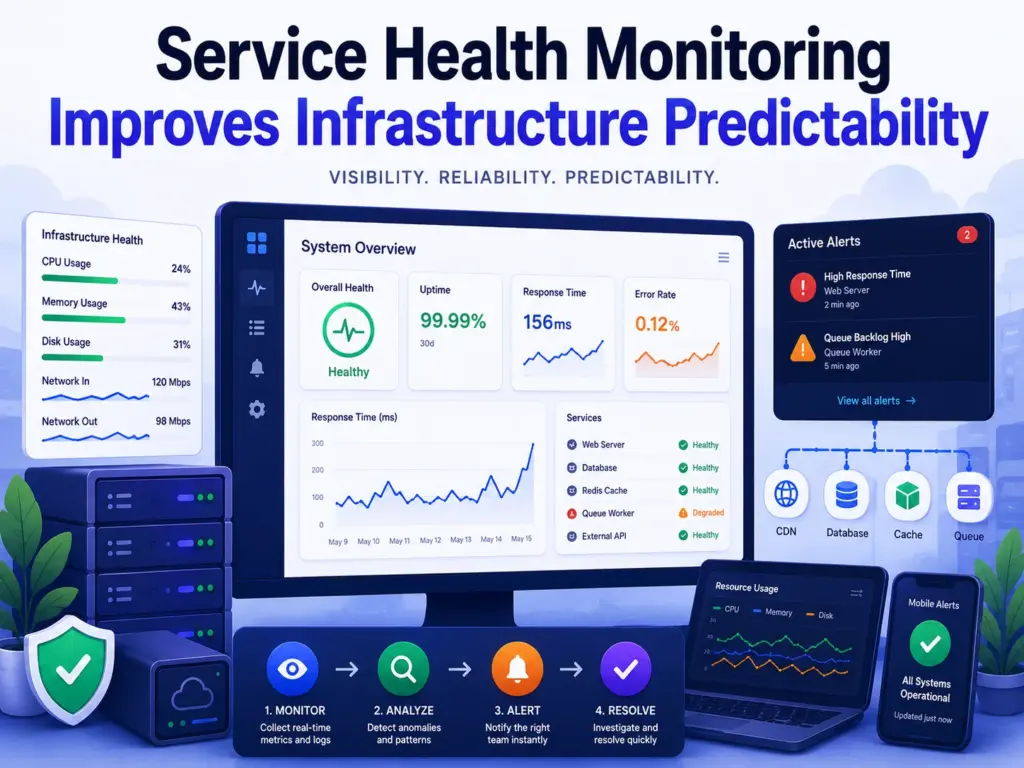
Infrastructure instability often develops silently before visible failures occur. Initially, systems may appear operational. However, latency spikes, failing services, overloaded queues, and degraded dependencies gradually reduce reliability. Consequently, reactive monitoring becomes insufficient. Many hosting environments focus heavily on uptime percentages while overlooking behavioral degradation indicators. In practice, predictability depends on visibility depth rather than basic […]