
Hosting instability rarely comes from traffic volume alone.
Most infrastructure failures occur because traffic is distributed inefficiently across systems. When requests concentrate unevenly, servers overload unpredictably and applications experience instability under changing demand.
Structure determines operational resilience.
At Wisegigs.eu, infrastructure audits consistently show that hosting instability is often caused by fragmented traffic distribution architecture rather than insufficient hardware capacity. Systems may contain adequate resources, yet poor request routing introduces avoidable bottlenecks.
Predictable traffic distribution improves hosting stability.
Structured routing reduces operational variability.
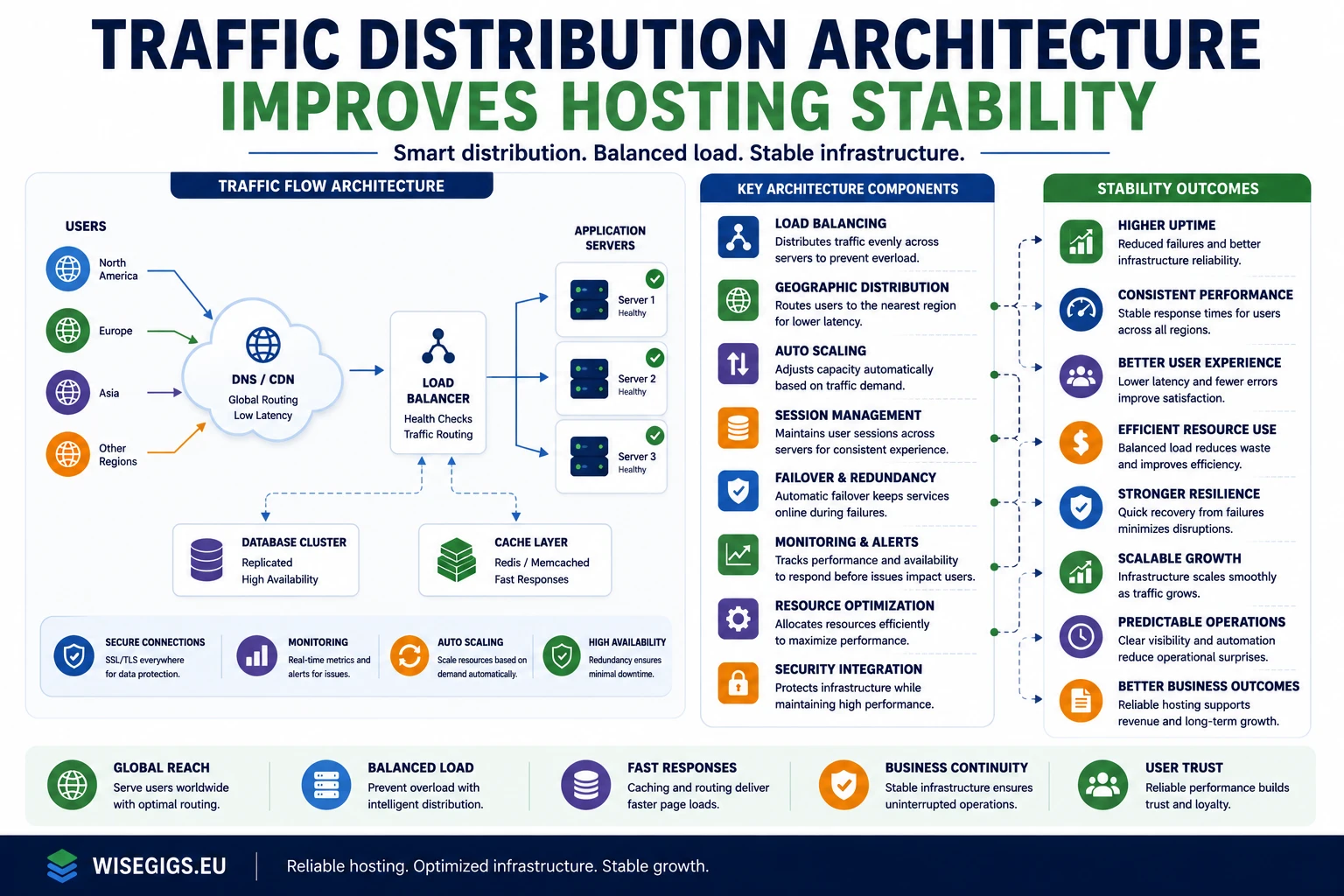
Traffic Distribution Defines Infrastructure Behavior
Every hosting environment processes incoming requests.
Unstructured distribution creates uneven workloads. Consequently, some systems become overloaded while others remain underutilized.
Clear traffic architecture balances operational demand.
Common distribution inconsistencies include:
- uneven request allocation
- fragmented routing logic
- inconsistent load balancing rules
- missing failover coordination
Structured distribution improves resource balance.
Balanced workloads improve hosting stability.
Load Balancing Improves Request Consistency
Load balancers control request flow.
Poor balancing strategies create instability. As a result, servers experience unpredictable resource spikes.
Clear load balancing improves delivery consistency.
Common balancing inconsistencies include:
- static routing without adaptability
- inconsistent health checks
- fragmented balancing policies
- overloaded primary nodes
Structured balancing improves request predictability.
Predictable routing improves operational stability.
NGINX explains how load balancing improves system reliability:
https://docs.nginx.com/nginx/admin-guide/load-balancer/
Geographic Distribution Improves Latency Stability
Traffic often originates from multiple regions.
Centralized delivery increases latency variability. Consequently, users experience inconsistent response times.
Clear geographic distribution improves performance consistency.
Common geographic inconsistencies include:
- single-region traffic concentration
- fragmented CDN deployment
- inconsistent edge routing
- missing regional failover systems
Structured geographic routing improves latency control.
Stable latency improves hosting reliability.
Auto Scaling Coordination Improves Capacity Stability
Traffic demand fluctuates continuously.
Without scaling coordination, systems struggle under sudden spikes. As a result, applications become unstable during high demand.
Clear scaling architecture improves capacity responsiveness.
Common scaling inconsistencies include:
- delayed instance provisioning
- fragmented scaling triggers
- inconsistent threshold configuration
- missing resource prioritization
Structured scaling improves operational continuity.
Responsive infrastructure improves hosting stability.
AWS documentation explains scaling coordination principles:
https://docs.aws.amazon.com/autoscaling/
Session Management Improves Distribution Reliability
Applications frequently maintain active sessions.
Unstructured session handling creates routing instability. Consequently, user experiences become inconsistent during scaling events.
Clear session architecture improves continuity.
Common session inconsistencies include:
- missing session persistence logic
- fragmented cache synchronization
- inconsistent authentication handling
- overloaded session storage systems
Structured session management improves request consistency.
Consistent sessions improve operational reliability.
Failover Architecture Improves Infrastructure Resilience
Failures are unavoidable in distributed systems.
Without failover planning, downtime escalates rapidly. As a result, infrastructure recovery becomes unpredictable.
Clear failover architecture improves resilience.
Common failover inconsistencies include:
- missing redundancy systems
- inconsistent backup routing
- fragmented recovery workflows
- unclear escalation behavior
Structured failover systems improve continuity.
Reliable recovery improves hosting stability.
Monitoring Integration Improves Distribution Visibility
Traffic distribution requires operational visibility.
Without monitoring, routing issues remain hidden. Consequently, performance degradation spreads unnoticed.
Clear monitoring integration improves awareness.
Key monitoring areas include:
- traffic allocation patterns
- server response times
- scaling event behavior
- load balancer performance
Structured monitoring improves operational control.
Visible infrastructure improves reliability.
Resource Allocation Alignment Improves Performance Predictability
Traffic distribution affects infrastructure utilization.
Poor resource alignment increases variability. As a result, systems waste capacity or overload unexpectedly.
Clear allocation alignment improves efficiency.
Common allocation inconsistencies include:
- underutilized secondary nodes
- fragmented CPU allocation
- inconsistent memory balancing
- uneven storage utilization
Structured allocation improves scalability.
Efficient systems improve hosting consistency.
What Reliable Traffic Distribution Architectures Prioritize
Stable hosting environments depend on predictable request handling.
Reliable infrastructures typically prioritize:
- balanced traffic allocation
- adaptive load balancing systems
- geographic request distribution
- coordinated auto scaling
- structured session management
- resilient failover architecture
- integrated monitoring visibility
- aligned resource allocation
These characteristics reduce operational bottlenecks.
Reduced bottlenecks improve hosting stability.
At Wisegigs.eu, infrastructure strategy focuses on structuring traffic distribution systems to improve scalability, operational resilience, and long-term hosting reliability across dynamic workloads.
Structured distribution improves infrastructure predictability.
Need help improving your hosting infrastructure for more stable traffic handling?
Contact Wisegigs.eu