
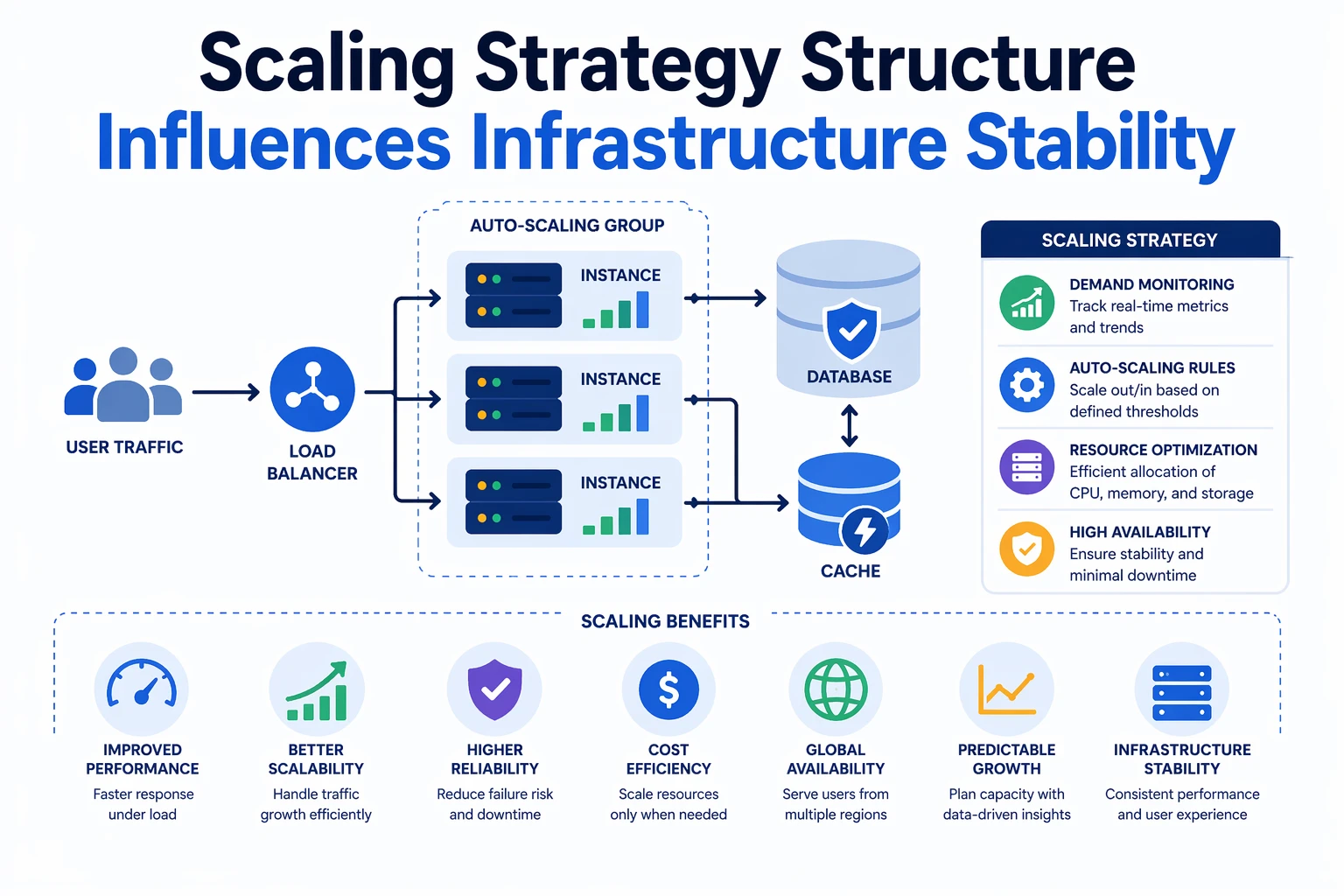
Infrastructure stability depends on predictable capacity behavior.
Traffic patterns rarely remain constant. Demand fluctuates due to marketing activity, seasonal variation, and user growth trends. Systems must adapt to these changes without introducing latency instability or availability degradation.
Scaling structure influences performance continuity.
When scaling logic remains consistent, capacity adapts predictably. When scaling logic becomes reactive or fragmented, instability increases.
At Wisegigs.eu, infrastructure audits frequently identify performance volatility caused by inconsistent scaling configuration rather than insufficient hardware resources. Systems often have enough capacity, yet scaling triggers activate too late or too aggressively.
Predictable scaling improves operational stability.
Structured capacity logic improves availability reliability.
Load Pattern Visibility Influences Scaling Accuracy
Scaling decisions depend on measurable demand signals.
Unobserved load variation reduces response accuracy.
Traffic patterns commonly vary across:
peak usage hours affecting resource consumption intensity
campaign-driven traffic spikes increasing concurrent request volume
regional traffic variation affecting latency distribution
unexpected growth trends affecting capacity requirements
Observable patterns improve scaling predictability.
Predictable demand improves provisioning accuracy.
AWS documentation explains how load monitoring improves scaling responsiveness:
https://docs.aws.amazon.com/autoscaling/
Clear signals improve infrastructure stability.
Horizontal Scaling Improves Traffic Distribution Stability
Horizontal scaling distributes traffic across multiple instances.
Distributed workloads reduce pressure on individual servers.
Overloaded single instances introduce performance bottlenecks.
Common horizontal scaling benefits include:
parallel processing improving request handling capacity
traffic distribution improving response consistency
failure isolation reducing outage probability
gradual scaling improving resource allocation control
Balanced distribution improves system stability.
Stable distribution improves performance predictability.
Cloudflare explains distributed infrastructure benefits:
https://www.cloudflare.com/learning/performance/what-is-load-balancing/
Load balancing improves availability continuity.
Vertical Scaling Influences Resource Allocation Precision
Vertical scaling increases available resources within existing instances.
Increased CPU or memory capacity improves workload processing capability.
Improper scaling increments introduce inefficiency risk.
Common vertical scaling considerations include:
memory allocation affecting application execution stability
CPU capacity affecting processing throughput continuity
disk performance affecting data retrieval latency
resource imbalance affecting bottleneck probability
Balanced resource allocation improves performance predictability.
Predictable capacity improves response consistency.
Controlled allocation improves infrastructure stability.
Load Balancing Structure Influences Availability Reliability
Load balancing distributes requests across available infrastructure nodes.
Imbalanced distribution introduces uneven workload pressure.
Uneven pressure increases failure probability.
Common load balancing structures include:
round-robin distribution ensuring equitable request allocation
weighted distribution prioritizing higher capacity nodes
health checks removing failing nodes from request routing
geographic routing improving latency stability
Balanced routing improves request continuity.
Stable routing improves performance predictability.
NGINX documentation explains load distribution logic:
https://nginx.org/en/docs/http/load_balancing.html
Structured routing improves system reliability.
Auto-Scaling Triggers Influence Response Timing
Scaling triggers define when infrastructure capacity adjusts.
Delayed triggers increase overload exposure.
Overly sensitive triggers introduce resource inefficiency.
Common trigger inconsistencies include:
threshold values ignoring traffic growth velocity
scaling cooldown periods delaying response adjustment
insufficient monitoring granularity affecting decision accuracy
misaligned scaling thresholds affecting resource availability
Accurate triggers improve scaling timing predictability.
Predictable timing improves performance continuity.
Balanced triggers improve infrastructure stability.
Stateless Architecture Improves Scaling Flexibility
Stateless systems separate application logic from session persistence.
Decoupled session management improves instance interchangeability.
Interchangeable instances improve scaling adaptability.
Common stateless advantages include:
independent request processing improving distribution efficiency
simplified replication improving horizontal scalability
reduced dependency complexity improving resilience predictability
improved failure recovery continuity
Flexible architecture improves scaling predictability.
Predictable behavior improves availability stability.
Capacity Planning Improves Long-Term Scaling Reliability
Scaling strategy requires long-term resource forecasting.
Unplanned growth increases infrastructure stress probability.
Predictive planning improves provisioning accuracy.
Common planning considerations include:
expected traffic growth rate patterns
anticipated campaign traffic intensity changes
application complexity evolution trends
database growth affecting performance continuity
Forecast clarity improves scaling readiness.
Prepared capacity improves performance stability.
Predictable growth improves infrastructure reliability.
Monitoring Integration Improves Scaling Precision
Scaling accuracy depends on observable system signals.
Incomplete monitoring reduces decision accuracy.
Comprehensive monitoring improves scaling responsiveness.
Common monitoring indicators include:
CPU utilization trends indicating processing pressure
memory consumption patterns indicating allocation requirements
request latency patterns indicating performance variation
error rate patterns indicating instability exposure
Clear signals improve scaling adjustment precision.
Precise adjustment improves infrastructure predictability.
Observable infrastructure improves reliability stability.
What Reliable Scaling Structures Prioritize
Stable infrastructure performance depends on predictable capacity adjustment behavior.
Reliable scaling strategies typically prioritize:
clear load visibility signals
balanced horizontal distribution logic
optimized vertical resource allocation structure
predictable load balancing configuration patterns
accurate auto-scaling trigger calibration
stateless architecture enabling flexible distribution
continuous monitoring supporting adjustment accuracy
These characteristics reduce overload probability.
Reduced overload improves availability predictability.
At Wisegigs.eu, scaling architecture focuses on minimizing variability introduced by reactive infrastructure adjustments.
Predictable scaling improves long-term performance continuity.
Structured capacity management improves infrastructure stability.
Need help designing infrastructure scaling strategies for predictable performance growth?
Contact Wisegigs.eu